Robots.txt — зачем он нужен и как его настроить
robots.txt — это текстовый файл с инструкциями для поисковиков.
В этом файле можно закрыть сайт от поисковых систем или же закрыть отдельные страницы / разделы сайта. Можно прописывать правила как для конкретного поисковика, так и для всех поисковиков сразу.
Найти роботс можно по адресу: https://site.ru/robots.txt (где site.ru — это ваш домен).
robots.txt — это обязательный файл. Его отсутствие или кривая настройка могут вырасти в нереальный геморрой и сильно усложнить продвижение сайта.
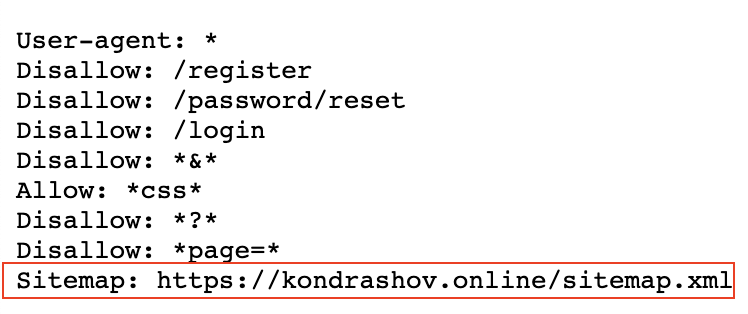
Пример robots.txt моего сайта
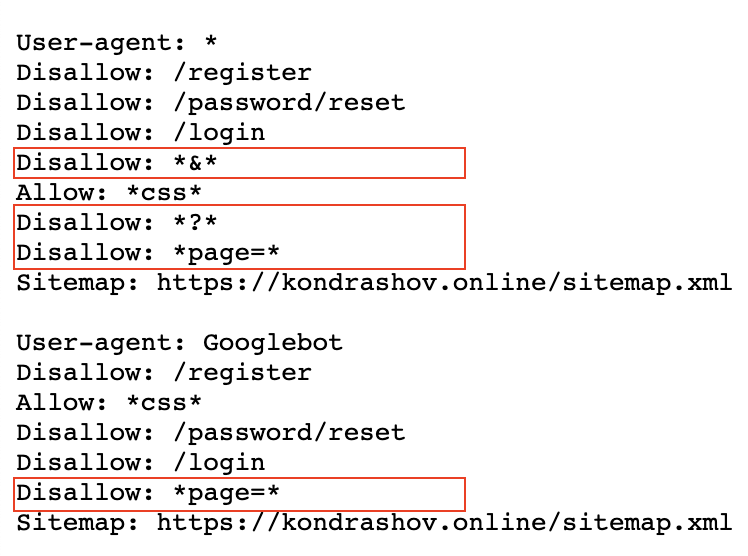
Разберем базовые директивы:
- User-agent: обращаемся к поисковому роботу по имени, либо ко всем роботам сразу
- Disallow: нужен для закрытия от индексации страниц, разделов, либо всего сайта
- Allow: разрешить индексацию отдельного раздела или страницы сайта
- Sitemap.xml: указать место расположения xml карты сайта
Дополнительные директивы для яндекса:
- Clean-param: очистить адреса от параметров (динамических переменных)
- Crawl-delay: поставить задержку при ответе поисковому роботу (если вдруг ваш сервак не справляется и поисковик кладёт сайт).
Как настраивать robots.txt
1. Создаем .txt файл с именем robots.txt и вписываем первой строкой:
User-agent: *
Эта директива указывает на то, что любой поисковой робот может воспользоваться ниже указанными правилами, если не найдет определенных правил, конкретно для себя.
2. Скрываем от поисковиков технические страницы:
- Панель администрирования сайта
- Поиск по сайту
- Страницы с неуникальной информацией (политика конфиденциальности и т.д.)
В моем случае, нужно закрыть:
- Disallow: /register
- Disallow: /password/reset
- Disallow: /login
Просто подставьте свои адреса вместо адресов из примера. По необходимости добавьте еще несколько директив Disallow (если таких страниц у вас больше 3-х)
3. Закрываем от индексации URL с параметрами:
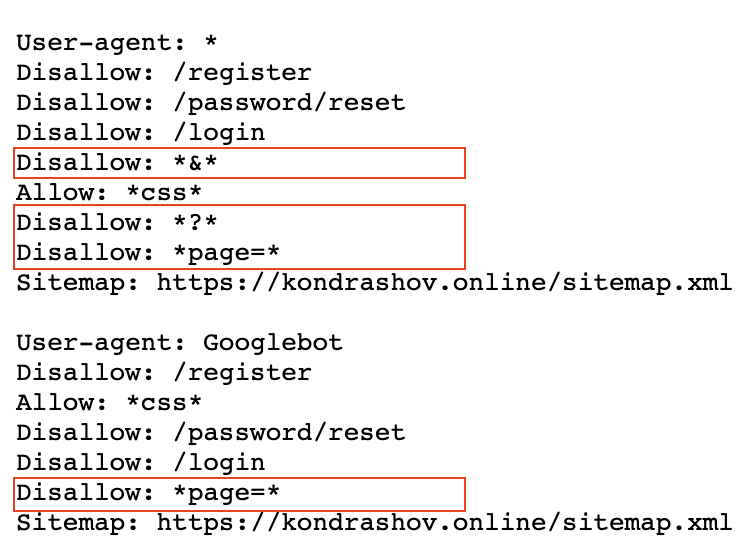
URL с параметрами — это страницы, в адрес которых дописываются атрибуты в результате работы сортировок, фильтров, и других элементов.
Наример, когда вы переходите по пагинации на моем сайте.
Наример, - когда вы переходите по пагинации на моем сайте.
В синий прямоугольник я выделил постоянный адрес,
а в красный — подставляемые параметры при переходе по пагинации.
Чтобы закрыть от индексации всю пагинацию на моем сайте, нужно воспользоваться следующей директивой:
Disallow: *page=*
Символ * указывает роботу, что нет значения, что идет перед началом и концом записи нашей константы.
URL, которые будут закрыты в результате работы директивы:
- https://kondrashov.online/?page=любой_текст
- https://kondrashov.online/любой_текст?page=3/любой_текст
- https://kondrashov.online/любой_текст/?page=21231231
Если робот найдет в адресе страницы фрагмент "page=", то он не станет индексировать эту страницу. Сама же страница может быть любого уровня вложенности.
Рассмотрим работу переменных в интернет магазине
Возьмем случайный интернет магазин, отправимся на страницу каталога и кликнем в какую-нибудь сортировку товаров:
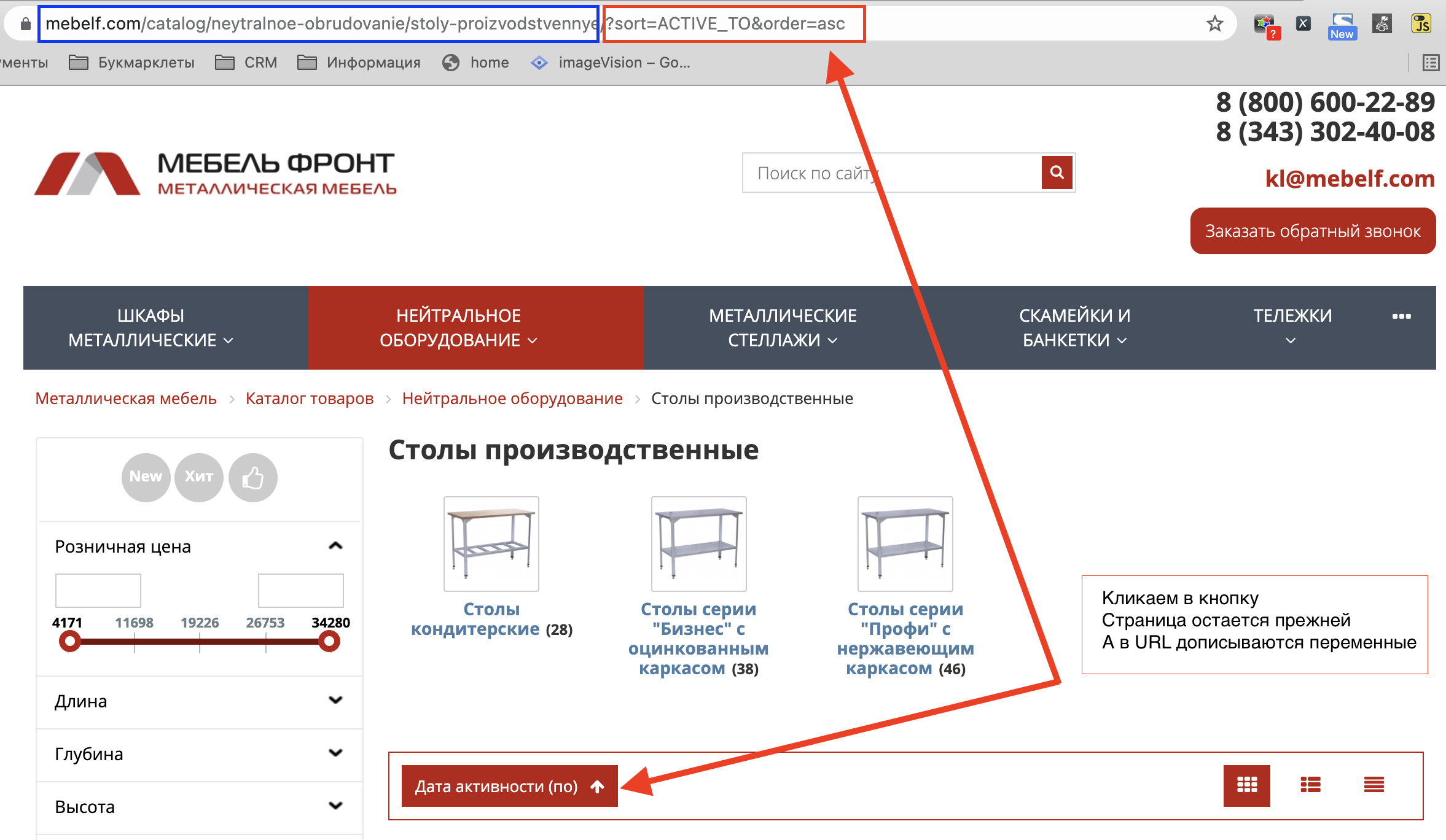
По умолчанию у нас статические адрес страницы, без переменных в адресе.
При использовании каких-либо сортировок и фильтраций адрес начинает меняться. К нему добавляются переменные (красный прямоугольник на скриншоте).
Страница при этом остается прежней, на ней меняется только порядок товаров.
Такие страницы не являются полезными для поисковика, они воспринимаются как дубли основной страницы.
- Подробнее читайте тут: некачественные страницы yandex
- И еще тут: поиск и удаление дублей на сайте
Наша задача — понять, какие есть способы образования таких страниц, и закрыть их от индексирования!
В моем примере я отсортировал товары по актуальности, и адрес изменился.
В нем появился вот такой тест: ?sort=ACTIVE_TO&order=asc
Параметры генерируются через переменную ?sort. Понимая это, я могу дописать в наш robots.txt новую директиву:
Disallow: *?sort*
Тем самым я закрою от индексации все страницы, в которых встречается переменная ?sort, по аналогии с первым примером.
Любые динамические адреса генерируются через символы: ?, $, &, =, %
Если закрыть все адреса, в которых встречаются эти символы, то мы избавимся от всех дублей страниц с параметрами.
- Disallow: *?*
- Disallow: *$*
- Disallow: *&*
- Disallow: *=*
- Disallow: *%*
Но такая глобальная зачистка может зацепить и важные страницы сайта!
4. Открываем доступ к файлам стилей сайта CSS
Директива: Allow: *css* решит проблему доступности всех CSS файлов на сайте.
Адреса до CSS файлов могут содержать параметры. Есть риск, что при закрытии дублей страниц, мы можем закрыть и доступ к CSS. Поэтому после закрытия динамических страниц дописываем директиву Allow: *css*.
5. Указываем ссылку на Sitemap.xml
Самый простой пункт настройки — нужно поставить ссылку на карту сайта через директиву:
Sitemap: https://site.ru/sitemap.xml
Где site.ru — домен вашего сайта.
Все! Настройка закончена.
Мы настроили базовый robots.txt, который подойдет для любой CMS системы.
Если есть вопросы, пишите в комменты, разберем ;)
Некоторые важные моменты про robots.txt
- Robots.txt кешируется поисковиками, краткосрочно, но все же кешируется!
- Кодировка для robots.txt - UTF8
- Размер файла — не более 500кб.
- Код ответа сервера должен быть 200. Проверить можно тут: https://webmaster.yandex.ru/tools/server-response/
- Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера. Для указания имен доменов в зоне РФ используйте Punycode!
- Не закрывайте страницы пагинации от индексации в robots.txt (в своем примере я делаю в точности наоборот, но у меня есть свои причины на это). Для закрытия страниц пагинации используйте теги: noindex, follow или rel="canonical".

Все рекомендации, инструкции, советы проверены мной на пачке проектов.