Некачественные страницы в Yandex Webmsater
Когда вы открываете сайт, то видите его содержимое: дизайн, красочные картинки, текст, видеоролики и т.п.
Поисковая система видит его несколько по-другому

Поисковик работает с HTML-языком разметки гипертекста. И каждая страница для него выглядит как строчки HTML-кода, непонятного простым обывателям. Вебмастеру же, следует уделить изучению кода большую часть времени.
Для того чтобы ПС лучше ранжировала (выше показывала) ваш сайт, необходимо сделать внутреннее содержимое "понятнее" для нее. Это и есть поисковая оптимизация.
Некачественные страницы - это плохо оптимизированные страницы, которые не несут полезной информации для пользователя. И главной задачей любого веб-мастера (SEO специалиста), который следит за посещаемостью сайта, является оптимизация таких страниц.
ПС исключает некачественные (или недостаточно качественные) страницы из поиска. И с этим можно и нужно бороться. Появление таких страниц приводит к падению трафка и негативно сказывается на результатах продвижения (причем, в Google алгоритм определения качества страниц отличается, и проблема может быть только у одного поисковика).
Основные причины исключения из поиска
- Страницы, которые не несут пользы или те, в которых содержится неуникальный текст. Часто встречается в интернет-магазинах. Производитель не дает качественную информацию о товаре, а веб-мастер не старается ее создать. Поэтому текста либо очень мало, либо его вообще нет, либо он в точности копирует описание с сайта-поставщика. Также некачественными признаются страницы, которые копируют друг друга на самом сайте (например, в интернет-магазине мебели в карточках шкафов все описания одинаковые).
- Заполнение мета-тегов по шаблону. Несколько страниц могут иметь одинаковые Title и Description. В некоторых системах управления (CMS) эта проблема возникает автоматически, и ее не получается решить без вмешательства веб-программиста. А некоторые контент-менеджеры вообще не обращают на мета-теги внимания. Запомните главное правило: Title и Description для каждой страницы должны быть индивидуальными и включать в описание поисковые запросы. К тому же они не должны дублировать друг друга.
- Неправильная структура заголовков. На каждой странице должен быть главный заголовок - H1. Это текст со шрифтом самого большого размера, заключенный в h1. Он идет перед основным текстом, в нем есть ключевые слова.
- Служебные страницы. Страницы панели администрирования, поиска по сайту, RSS. Их мы пропускаем, потому что в поисковой выдаче они все равно не нужны.
- Неправильный ответ сервера. Документы, которых не существуют (например, были перенесены или удалены). Для решения подобной проблемы необходимо перенаправлять сервер на нужный адрес или обрабатывать 404 ошибку.
Как найти некачественные страницы
- Зарегистрируйте сайт в Яндекс Вебмастере
- Выберите свой сайт и зайдите в раздел Индексирование > Страницы в поиске > Исключенные.

Прокрутите экран вниз, и вы увидите список некачественных страниц по мнению поисковика Яндекс
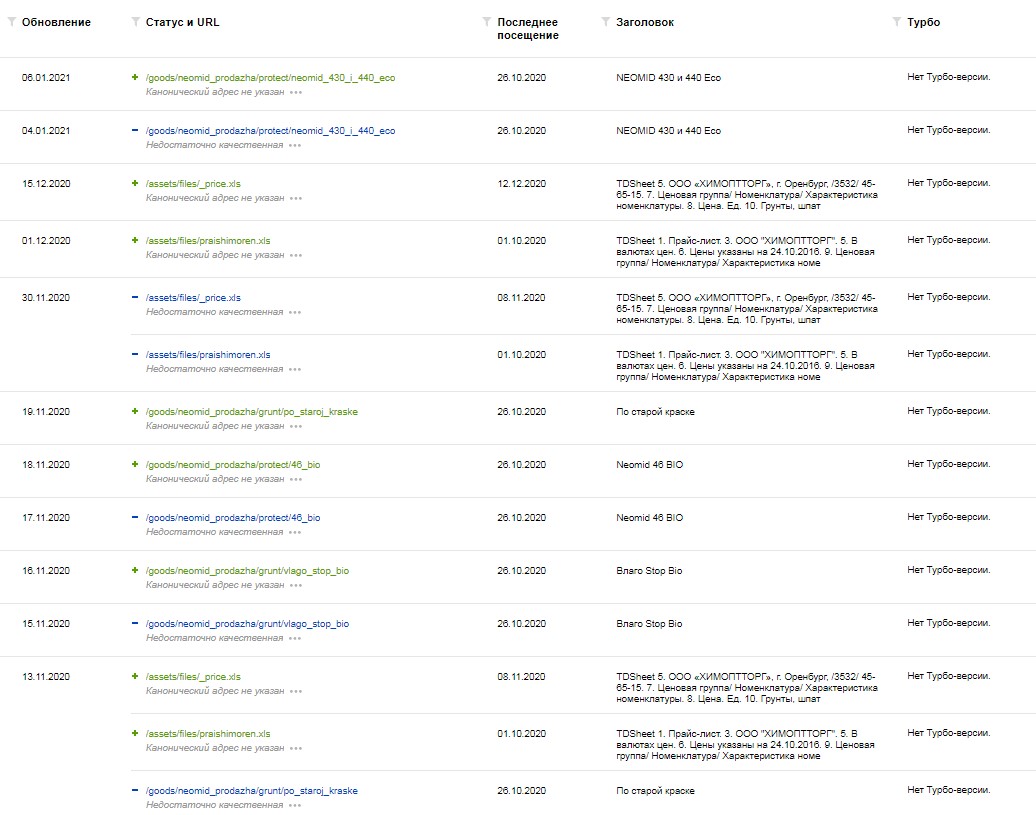
Рассмотрим одну из страниц в нашем примере, которую Яндекс указал как некачественную:
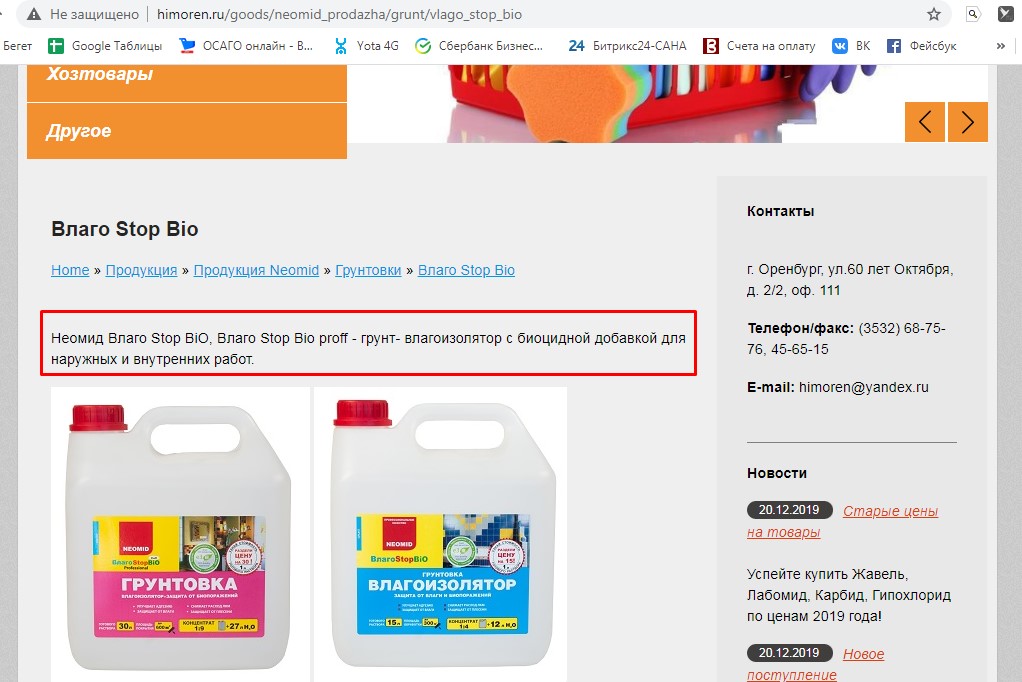
Она открывается, значит, не удалена и не перенесена. Визуально на ней есть заголовок, изображения и текст, но его слишком мало - всего 1 строчка. И если мы откроем HTML-код, то увидим, что Title и Description дублируют друг друга.

Прокручиваем код дальше и находим H1. Он на странице единственный, больше заголовков нет. Идет первым перед основным текстом. Здесь все в порядке.

Мы нашли, как минимум, две ошибки: мало текста и плохие мета-теги. Решение: необходимо разместить уникальный текст с полезным описанием товара и сделать мета-теги отличными друг от друга.
Интернет-магазины и некачественные карточки товаров
Многие CMS создают дубли страниц, не позволяют менять в карточках мета-теги. При использовании шаблонного дизайна заголовки на страницах размещаются по желанию дизайнера, который понятия не имеет, что такое SEO-оптимизация. Например, самый главный H1 может размещаться в шапке и дублироваться на всех страницах.
Что нужно сделать
- Найти все заголовки и выстроить их правильную структуру.
- Убрать все H1 заголовки из шаблона (например, заменить на SPAN и прописать стиль. И использовать их исключительно в тексте - ведь мы должны включать в заголовки ключевые запросы, которые для каждой страницы индивидуальные.
- Изменить все Title и Descriptons, сделать их уникальными.
- Разместить полное описание товара в каждой карточке. Оно должно быть уникальным.
- Избавиться от дублей страниц. Но как их найти в интернет-магазине, в котором тысячи товаров?
BatchUniqueChecker - бесплатная проверка на дубли
Подходит для любителей десктопных программ. Скачайте ее и откройте exe-файл. В настройках укажите шингл (количество слов подряд, которые проверяются на сходство). Рекомендуемый шингл - 3-4 слова. В программе есть небольшое неудобство - необходимо вставить URL всех страниц в виде списка или хml-файла (карты ссылок). Проще скачать с веб-сервера карту ссылок (sitemap.xml), которая создавалась в целях улучшения индексации, и загрузить ее в программу.
В программе есть небольшое неудобство - необходимо вставить URL всех страниц в виде списка или хml-файла (карты ссылок). Проще скачать с веб-сервера карту ссылок (sitemap.xml), которая создавалась в целях улучшения индексации, и загрузить ее в программу.
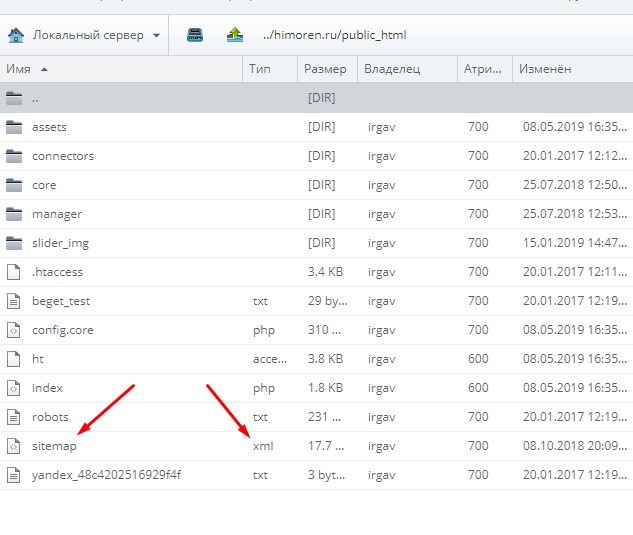 Импортируем файл для поверки.
Импортируем файл для поверки.

Мы получили список всех url сайта. Нажимаем кнопку "Проверить" и ждем окончание процесса.

Получаем список всех проблемных URL. В графе справа показана их уникальность.
- 0%- это очень плохо. Необходимо размещать уникальный контент.
- От 90-95% - хорошо. Со страницами, имеющими низкую уникальность, нужно работать.
- 100% - отлично.
В графе код ответа показаны проблемные веб-страницы, которые удалены. Но так как сервер возвращает 404 ошибку - в нашем примере все в порядке.
Рассмотрим страницу с 0% уникальности.
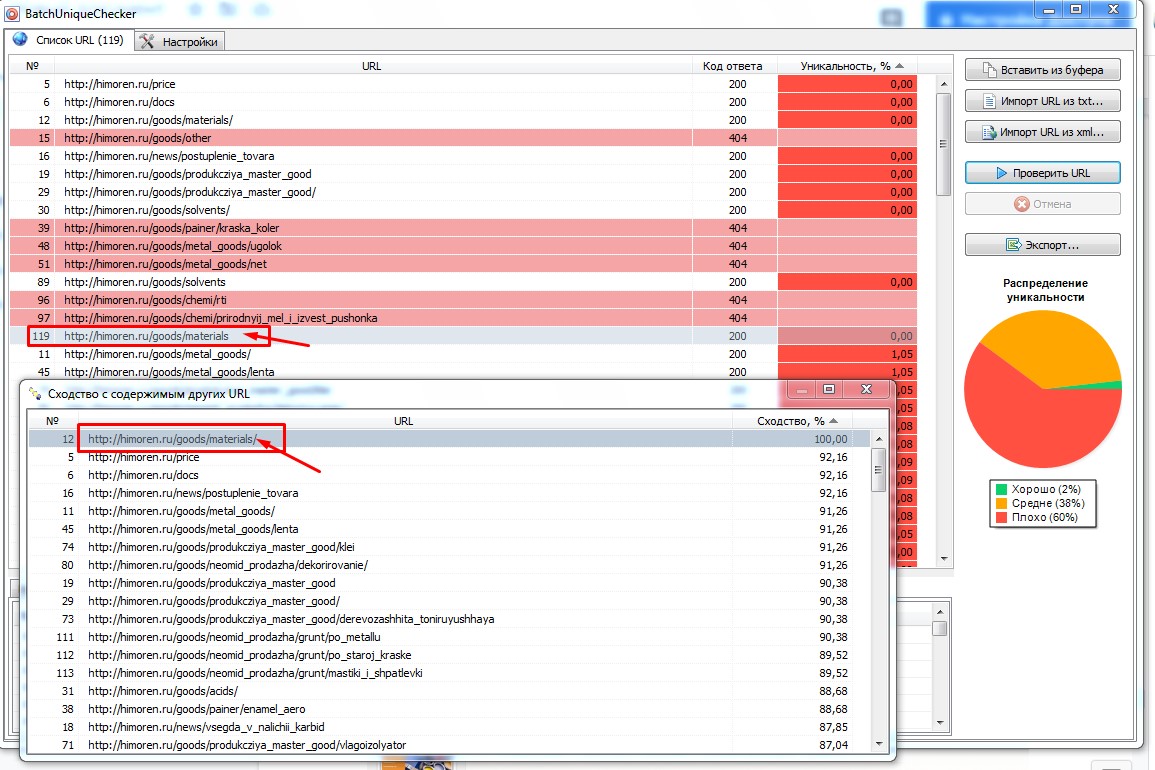
В нашем примере программа указывает на такой же URL, который отличается только слешем на конце - /. Для решения этой проблемы необходимо закрыть от индексации один из этих URL. Например, прописать в robots.txt правило, что все страницы с / на конце необходимо закрывать от индексации.
Еще одна страница из нашего примера дублируется с целым списком похожих URL.
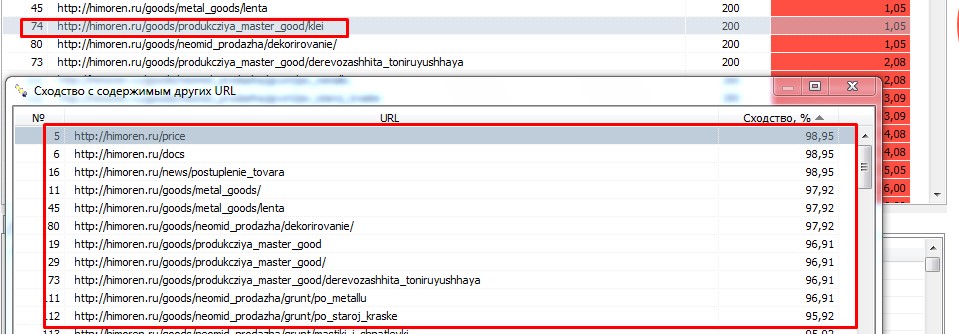
Если нажать на адрес в окне дубля, то мы получаем совершенно одинаковый текст. Уникальностью обладает только слово "клей":

В нашем примере дублируется адрес компании и новостная лента, которые сквозным образом размещены на всех страницах сайта.
Мы возвращаемся к той же проблеме: на страницах очень мало текста, поэтому он не считается весомым, или его нет вообще. Решение: разместить уникальный полезный контент.
Отслеживайте некачественные страницы через yandex.webmaster. Следите за индексом сайта и проверяйте сайт через BatchUniqueChecker каждые полмесяца.
Это позволит избежать больших проблем в SEO и сохранить позиции сайта.

Все рекомендации, инструкции, советы проверены мной на пачке проектов.