_80x60_33c.png)
_80x60_33c.png)
_80x60_33c.png)
_80x60_33c.png)
_80x60_33c.png)
Как найти и удалить дубли страниц на сайте


Порядок действий:
- Делаем полный скрининг сайта через программу Seo Screaming Frog (скачать можно с оф. сайта: https://www.screamingfrog.co.uk/seo-spider/ или с торрентов)
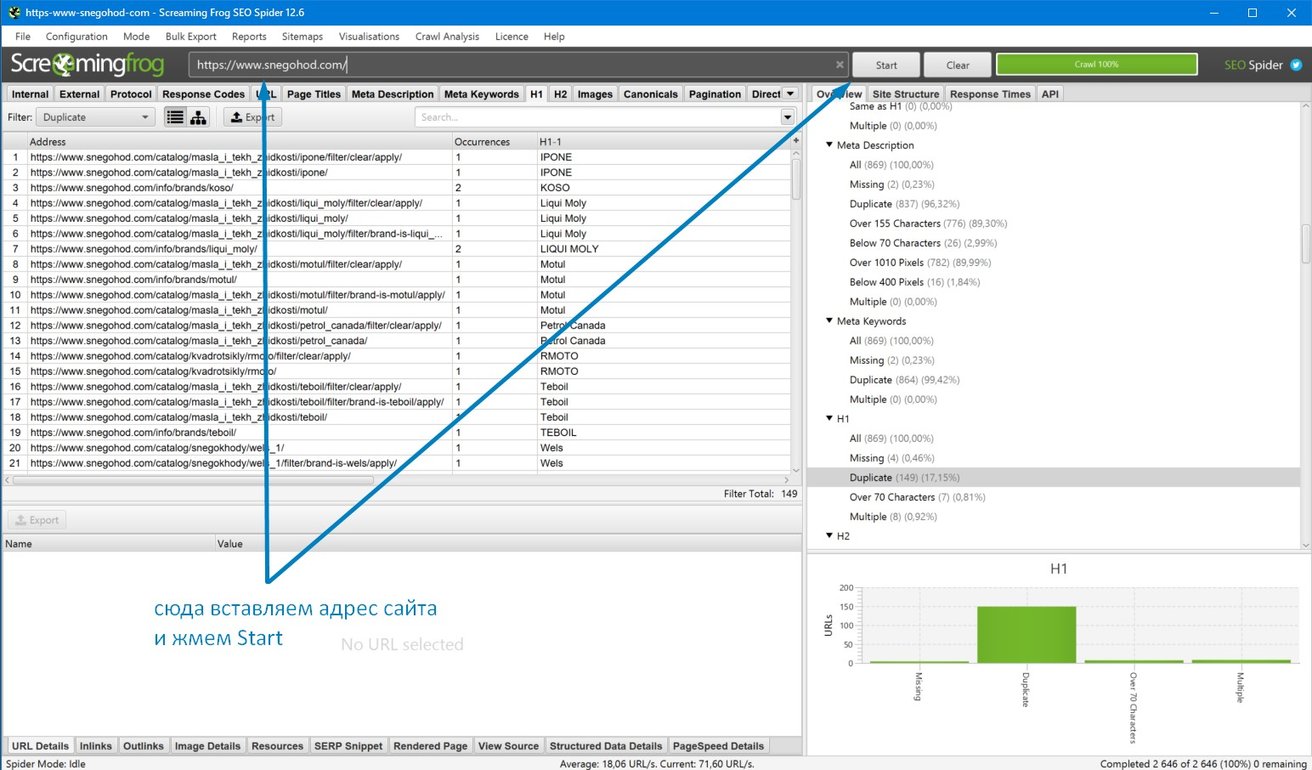
- Выгружаем дубли по заголовку H1 в Excel

Теперь разберемся, откуда на сайте появились страницы с одинаковыми заголовками. Вариантов тут немного: либо вы сами создали пачку дублей, либо же они сгенерировались автоматом.
90% дублей страниц я нахожу в следующих местах:
- Товарные фильтры интернет-магазинов
- Страницы пагинации (рубрики товаров, страницы блога, новостей и т.д.)
- Корзины товаров, работающие через URL с параметрами
- Незакрытые от индекса UTM метки (привет директологам)
Я тегирую дубли страниц по характеру их образования и сразу прикидываю, что с ними делать: удалять и склеивать, менять заголовок H1, или же закрывать от индексации.
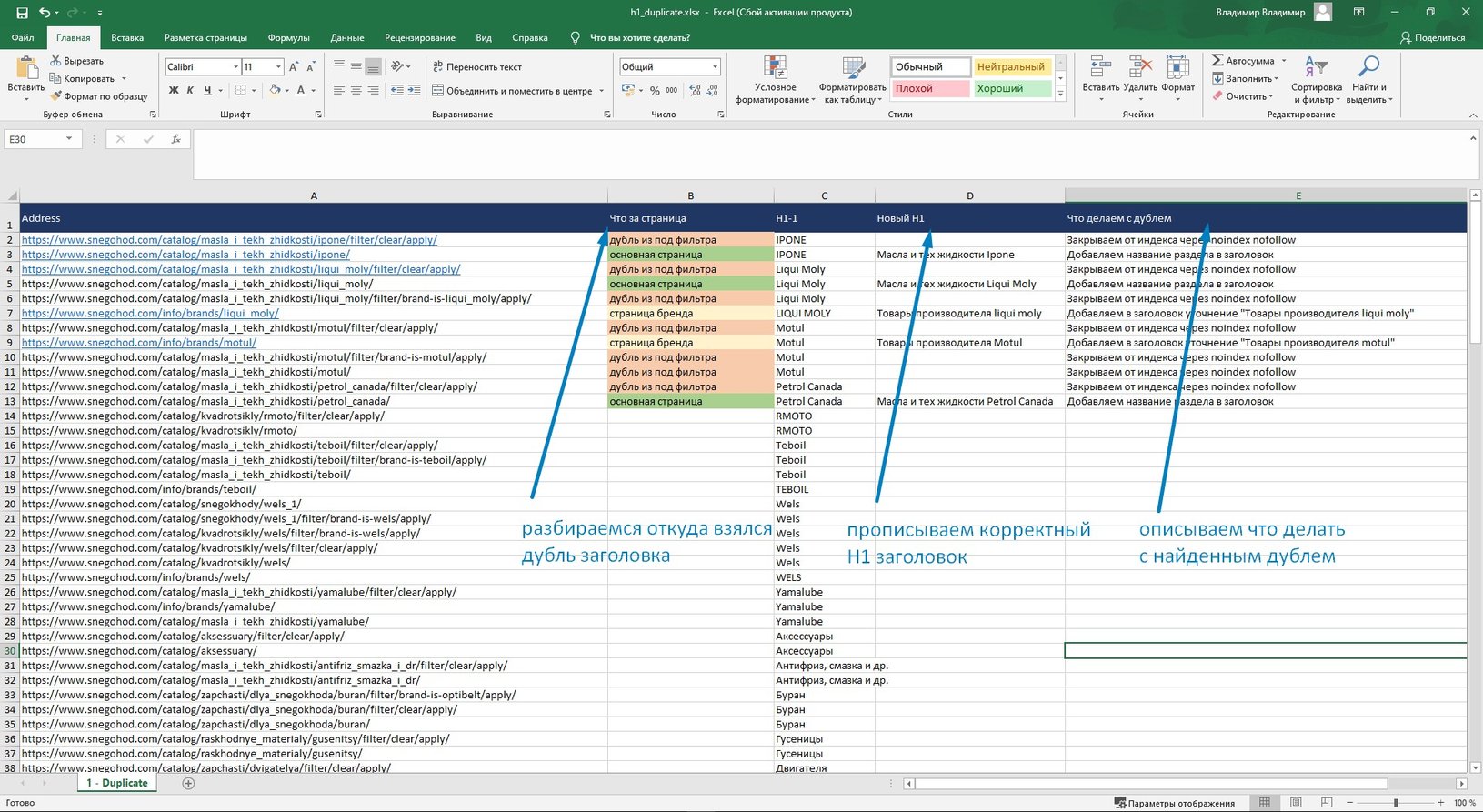
Удаление явных дублей страниц
- Страницы пагинации нужно клеить через: link rel="canonical" (каноничные страницы)
- Страницы фильтра закрываем от индексации через атрибут rel="nofollow"
- Неявные дубли страниц (те, что вы создали сами) удаляем и клеим через 301 редирект
После склейки страниц проверьте, не осталось ли битых ссылок.
Добавляем директивы в robots.txt
В дополнение нужно закрыть дубли в robots.txt
Для того чтобы закрыть от индексации URL, в которых есть знак "?", добавьте в robots.txt следующую строку:
- Disallow: *?*
Вместо знака вопроса можно добавить любой фрагмент дубликата страниц. Например:
Если в дублях страниц встречается фрагмент "filter": site.ru/category/filter/, то для того, чтобы закрыть все страницы-дубли, нужно добавить фрагмент:
- Disallow: *filter*
Пример:
- https://artameb.ru/catalog/meditsinskie_shirmy/ — оригинальная страница
Дубли из-под фильтра:
- https://artameb.ru/catalog/meditsinskie_shirmy/filter/height-from-1676/apply/
- https://artameb.ru/catalog/meditsinskie_shirmy/filter/price-base-from-4914/height-from-1676/apply/
У дублей в примере есть кое-что схожее, в них встречается " apply" и " filter".
Для того чтобы закрыть все возможные дубли страниц в моем случае, нужно добавить сл. директивы в robots.txt:
- Disallow: *filter*
- Disallow: *apply*
Виды дублей страниц
Я разделяю дубли на 2 типа:
- Явные – полный дубль страницы. Их генерируют движки сайтов (Битрикс, Wordpress, OpenCart, и др.). Как их искать и удалять мы разобрали выше.
- Неявные – похожая по смыслу страница, воспринимаемая поисковиком как дубль. Такие дубли создают сами пользователи по глупости. Как с ними работать — тема для отдельной статьи.
Не занимаемся спамом. Отправляем только полезные материалы.